Algoritmus neuronových sítí (což je jeden z typů strojového učení) se obvykle učí na velké sadě „trénovacích“ dat, která jsou předem popsaná a klasifikovaná. Na základě toho se neuronová síť, složená z velkého množství malých jednoduchých podprogramů, naučí rozpoznávat určitá pravidla a vzorce. Aplikací těchto rozpoznaných pravidel pak dokáže posuzovat i zcela nová data.
Pravidla se ale neuronová síť neučí explicitně. Není to totiž klasický program, ale spíše velká skupina (síť) malých relativně jednoduchých programů (simulovaných neuronů). Každý neuron se samostatně učí rozpoznávat pravidla, a pokud tento neuron přispěl ke správnému řešení, dostane odměnu a jeho vazba bude posílena. Tím se může neuronová síť postupně zdokonalovat a dokonce se může i sama trénovat (tzv. unsupervised learning).
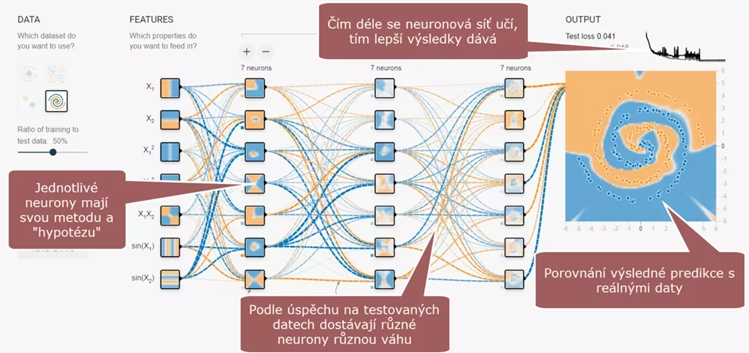
Schéma znázorňující jednoduchou neuronovou síť
V případě hlubokého strojového učení (deep learning) jde o neuronové sítě s neurony uspořádanými do velkého množství vrstev. Svým způsobem tak jde o několik neuronových sítí poskládaných za sebe. Pokud síť dojde ke špatnému závěru (například něco špatně rozpozná), dostane o této chybě informaci a „potrestá“ neurony, které se na chybě podílely, tím, že sníží jejich důležitost nebo změní jejich parametry. Výsledkem je postupné učení, které lze použít nejen na již známá data, ale i na úplně nová data, se kterými se síť nikdy nesetkala.